SharePoint™ Load Testing Services Case Study
Christopher L Merrill
©2009 Web Performance, Inc.
v1.0 - Feb 18, 2009
SharePoint™ Tuning
During the next series of tests, we focused on testing a single server, since there is little point in load testing and tuning a cluster of servers when the individual servers are not operating up to their potential.
A number of optimizations to the SharePoint™ configuration were suggested and implemented, including:
- Move static resources (images, etc) to an image library to facilitate caching of the resources in the browser
- Change SharePoint™ cache settings to Extranet Publishing Site
- Change the custom role provider to use Role Provider Caching
In addition, the Content Query Web Part was changed to handle taxonomy more efficiently. After each change was implemented, the system was tested to measure the change in performance. In each test, an improvement in bandwidth utilization was observed (particularly between the SharePoint™ servers and the database). However, the end-user performance was unchanged.
Next we tried to determine if the entire SharePoint™ installation would share this performance profile, or only the instance that was being tested. The customer created a new out-of-the-box SharePoint™ site using one of the example sites. This site was tested to 1500 users with only slight degradation seen at the peak. The test was very near (or past) the bandwidth limits of the network connection (a 45 Mbps DS-3).
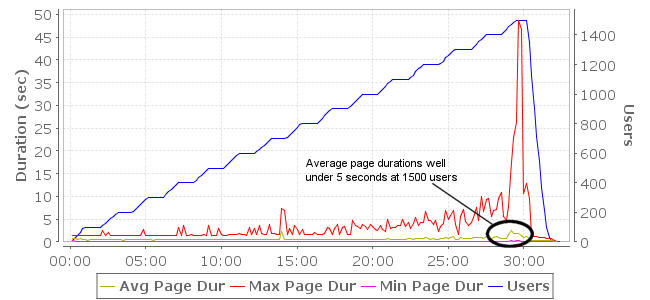
figure 4: Average page durations are greatly improved - under 5 seconds up to 1500 users
We were now convinced that the OS, hardware and SharePoint™ installation were healthy. We returned to the original site and targeted authentication. A new testcase was designed that visited 6 public pages as an unauthenticated user. The system was tested and scaled to 1000 users, but performance was poor with average page durations in the 10 second range. The system was stable, but performance had degraded rapidly by 1200 users (when we again hit the bandwidth limits).
Curious if the improved results of previous test were due to a lower number of unique pages visited, rather than authentication, we next designed a testcase that visited a larger number of pages, both authenticated and not. This included more pages than the first unauthenticated test, but a lot less than the original test scenario. This load test produced better performance, but was unstable – exhibiting a stalling behavior when under load. For example, the system was able to ramp up to 1300 users with the system serving ~30 pages/sec. As the test added more load, the system throughput suddenly dropped to less than 5 pages/sec. In multiple test runs, the stalling behavior was observed at varying load levels.
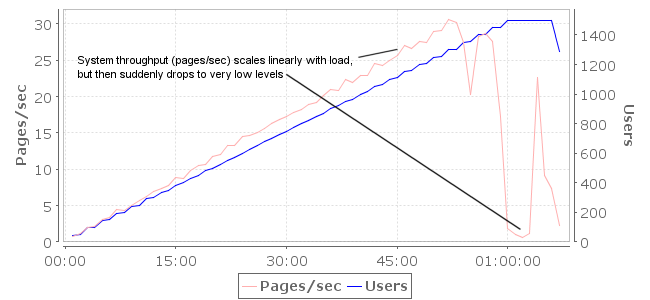
figure 5: System throughput scaled with load, then dropped to very low levels
The testcase was dissected in several iterations to determine if any particular group of pages performed better or worse than others, but no offenders were found. We again returned to a set of pages that did not require authentication – this time picking a larger set of pages containing a variety of features (27 pages total). Load tests revealed the system could service these pages with average page durations under 1 second at 1500 concurrent users with consistent throughput (~39 pages/sec) for 2 hours. Further experimentation revealed that the addition of one relatively simple testcase caused the system to become unstable. This gave us an easy way to demonstrate good and bad performance of the system under the same configuration (with different usage patterns). We hoped this would allow Microsoft Support Engineers to diagnose the problem.
During some of the previous tests, we also noticed that system performance sometimes degraded consistently from one test to the next. We subsequently discovered that rebooting the database between test runs temporarily improved performance. To help get consistency from the test results we began regularly rebooting all the servers prior to each test. This was good test practice to ensure a consistent testing environment. We came to realize that there is a larger significance to this particular symptom – although the realization did not come until later in the process (discussed later in this paper).
After looking at our test results as well as collecting their own data, Microsoft SharePoint™ Support indicated that SharePoint™ was apparently unable to make use of such large hardware (8 processors with 16G of RAM). In an effort to validate that the problem was indeed caused by the large hardware, they recommended that we reduce the number of processors to 4, and then later suggested reducing it to 2. In each case, this resulted in a surprising performance improvement but the stalling behavior remained. Reducing the number of processors moved the point of failure, allowing the system to run longer before stalling, but did not cure the problem. This proved that we had a problem unrelated to the size of the hardware that warranted more detailed, low level analysis.